fieldnotes

AgentMode under the microscope
2026-04-17
What’s this one all about then ?
We’ve been working a bit with the AWS Marketplace AgentMode feature recently. Its well-enough designed - compare a few specific products that come up in a search list or upload some requirements and find what matches and then dovetail into a proposal and agreement process process. Whether or not a buyer would be convinced to shortlist and or even choose a solution purely on the basis of AgentMode’s analysis is a different question - its probably useful for market research.
Observations
Four things stick out a bit funny with AgentMode from our testing.
1) AgentMode can compare a maximum of 5 products (this is a constraint of how many product IDs you
can shove onto the end of a URL like https://aws.amazon.com/marketplace/agentmode/#/?agent=comparison&listingIds=).
Now this in itself isn’t all that strange, a buyer does typically triage to a short list for a deeper dive. But its problematic if you got to AgentMode from some kind of a search with an AI overview and there were say 100 results and maybe 10-15 of them were analysed by the AI overview feature. You’re forced to break them up into groups, you can’t do an N-way comparison of a list longer than 5. Maybe with a logged in user they could allow a list of 10 ?
Also, you can’t compare 1 product (ie your own, if you are a vendor). You must do at least 2.
2) AgentMode seems blissfully unaware when you ask it to compare things that are very different (and are unlikely to be compared in the real world).
I’d like to compare an apple, a temple and a boat. Perhaps extreme but you can tell AgentMode to compare some very unlikely things, like a service to help AWS partners GTM, a security ISV product, and an financial markets capital optimization platform:
- Labra Partner Development Manager (PDM) on Demand for AWS ISV Alliance
- Drata Security & Compliance Automation Platform
- Kyriba: Your Liquidity Performance Platform
Putting that together (opens in a new window): an unlikely 3-way comparison between Labra, Drata and Kyriba
You will see AgentMode tries hard to make a comparison. Probably too hard - is that sycophantic AI ? And the comparison isn’t all that helpful. A guardrail that did some kind of “are these even in the same broad category and therefore can be legitimately compared” would probably be useful, even if that was just saving production inferencing costs for AWS themselves or preventing DDoS type overloads from people hitting up AgentMode with malicious payloads (ahem! don’t repeatedly hit that URL for fun).
3) It takes quite a long time to get a full result set, you should expect a 3-4 min wait, perhaps longer.
So if you decide to AgentMode leave early, you’ll end up with tabulated empty or partial comparisons. This is an issue both with the table on the web which actually progressively but slowly fills - you might have to make a coffee or hit refresh a few times to encourage it, as well as an issue with downloading PDF/CSV which is an interim semi-empty state unless the table itself has been completely filled by the AgentMode researcher.
Here’s some time-lapse screenshots of a reasonable comparison, focusing on the tabulation panel which ultimately brings the comparison together for a user:
15 sec
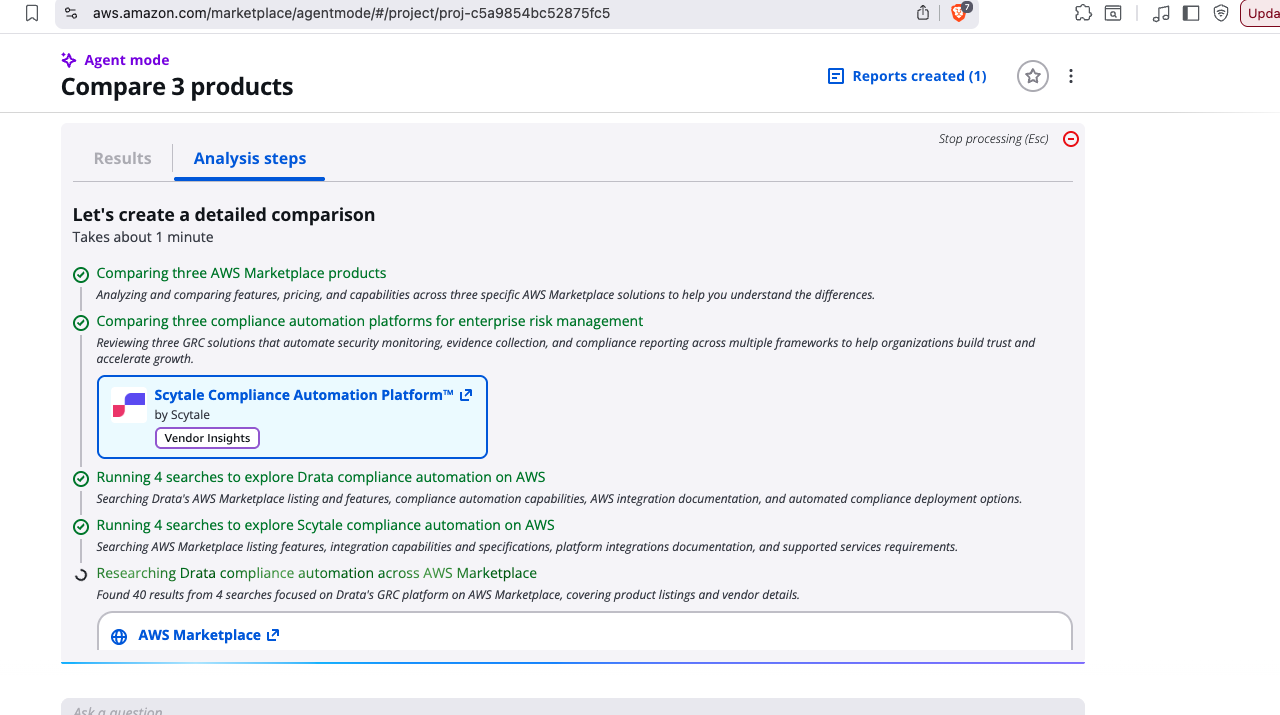
30 sec
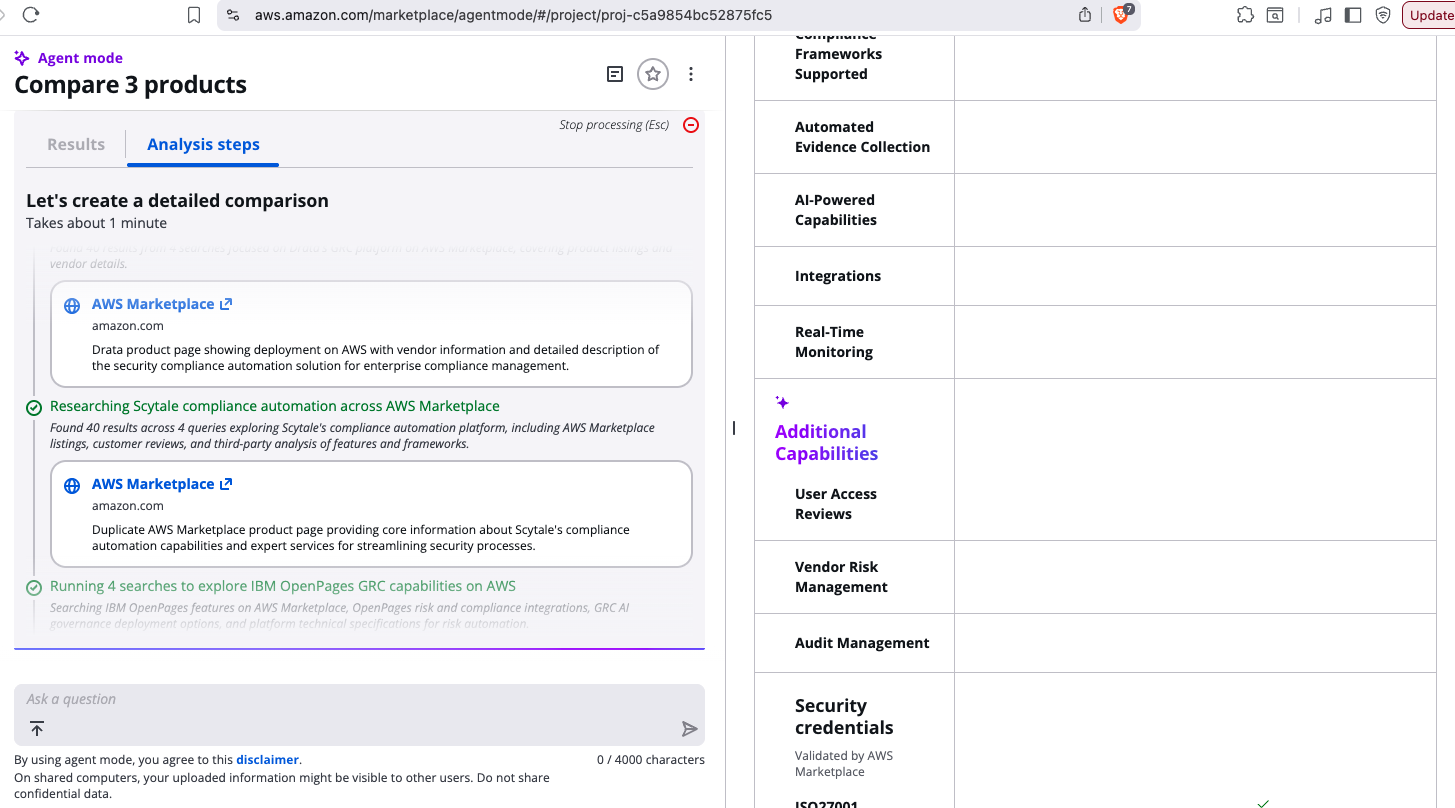
45 sec
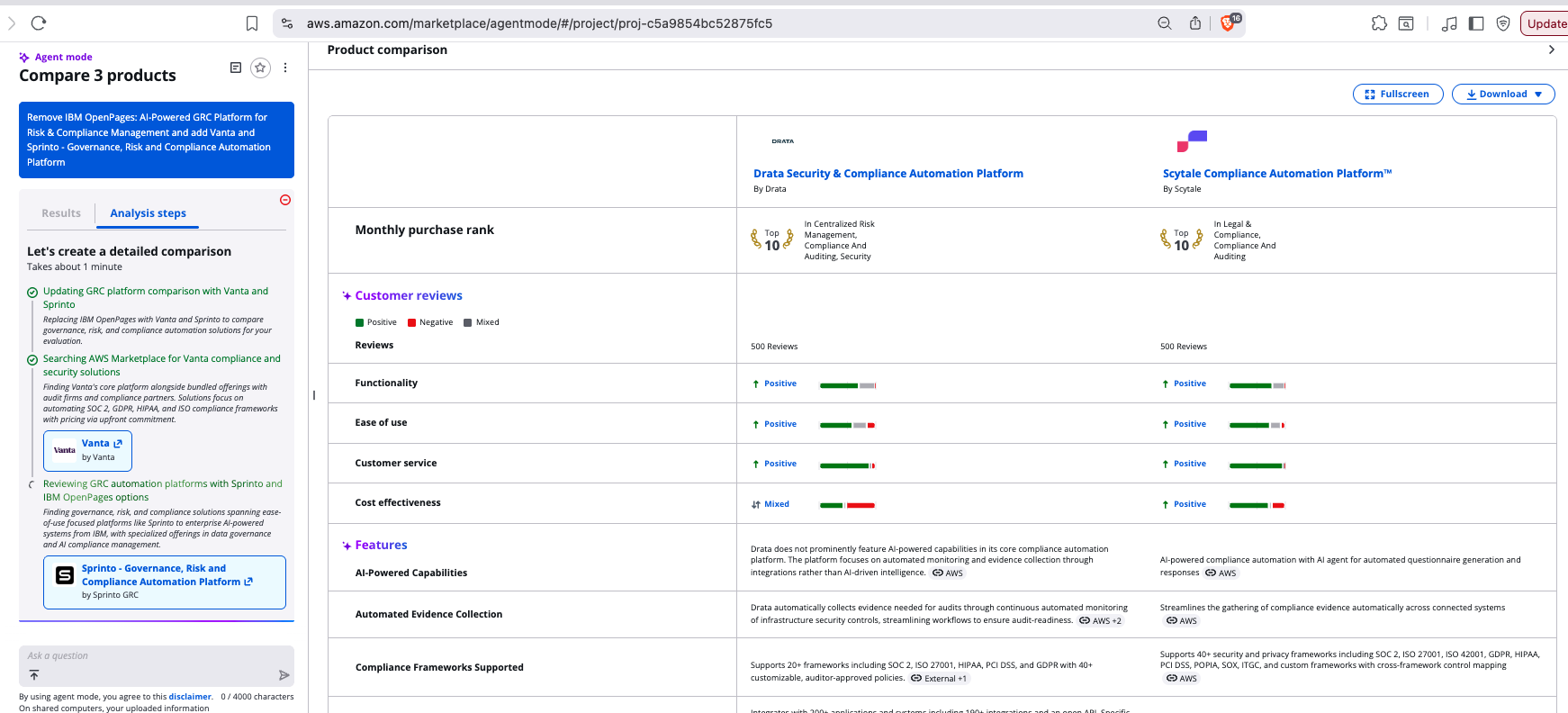
60 sec
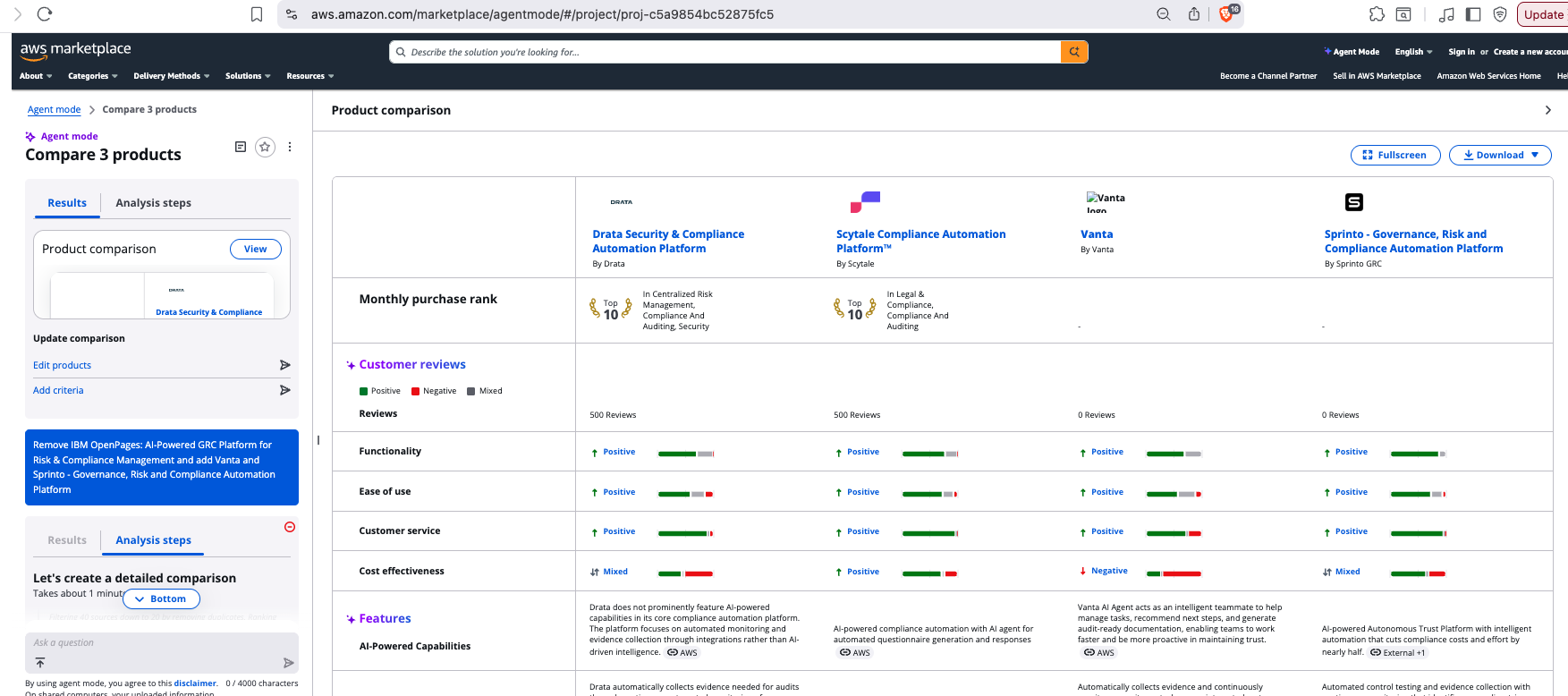
90 sec
We’ve done this a bunch of times (hundreds … over several weeks), and from those experiments our records show that 50% of AgentMode jobs finish within 2 min 40 sec (ie @p50), while 95% of AgentMode jobs finish within 4 min 15 sec (ie @p95). Longest wait for AgentMode to complete we have seen is 13 min and 51 sec (ie (@p100).
Whats the lesson ? Kick off your comparison and then wait 3-5 mins. Go make a coffee or play with the dog, then collect your results. Otherwise results are probably going to be incomplete and if you are relying on that data for insight and purchasing decisions YMMV.
Additional observation is if you have a mix of products in your AgentMode comparison set you’re likely to get faster results for the more common ones, and slower results for the lesser known ones (some kind of caching). Be sure to wait long enough for the lesser known ones to complete via the researcher, else you risk skewing the volume of output towards the more common solutions.
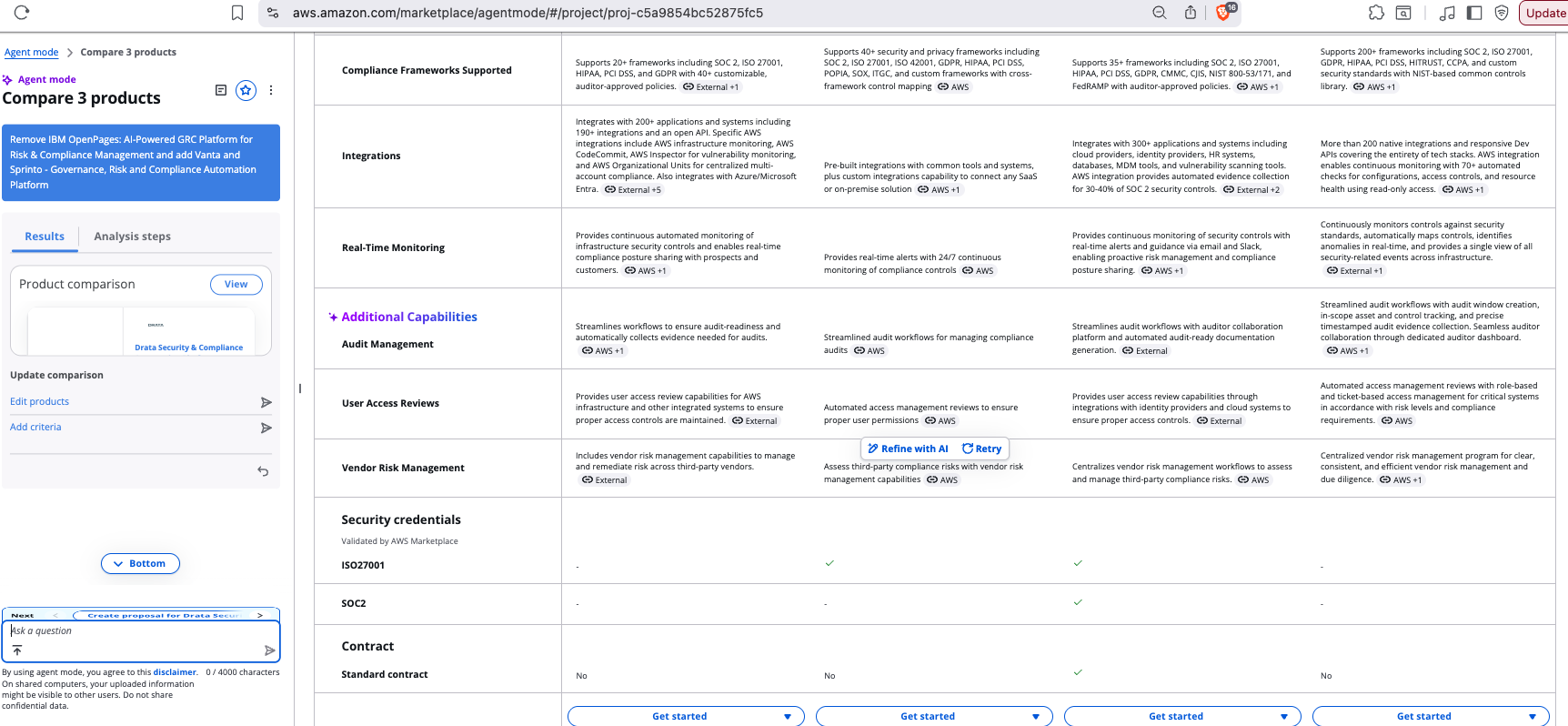
4) The AgentMode “evidence” in the form of its category/feature analysis and evidence is … sometimes questionable.
The researcher seems to grab highly rated over highly relevant/authoritative URLs and use those to make assessments, even when there is more structured detail in the marketplace entries themselves, and when the sources are potentially biased (eg one vendor writing an “objective” review of products in its space and selectively comparing them against itself to make a point). Here’s two: we are comparing two GRC automation products, Drata vs Delve, and a bunch of the Delve evidence is coming from Sprinto (another GRC automation competitor) including their analysis of Delve vs yet another competitor, Vanta.
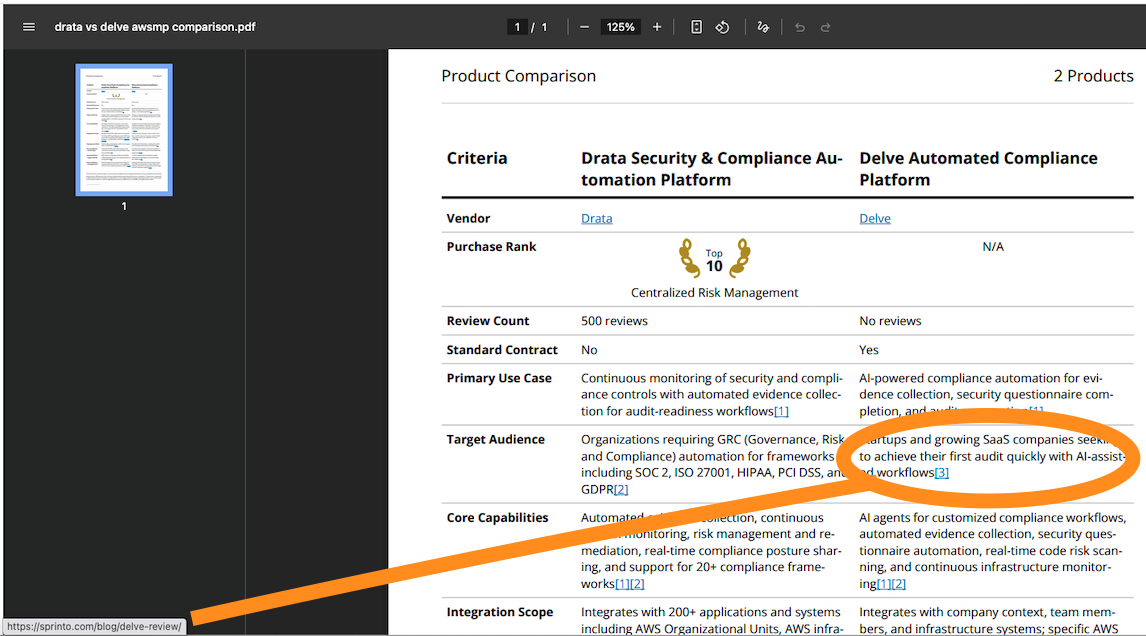
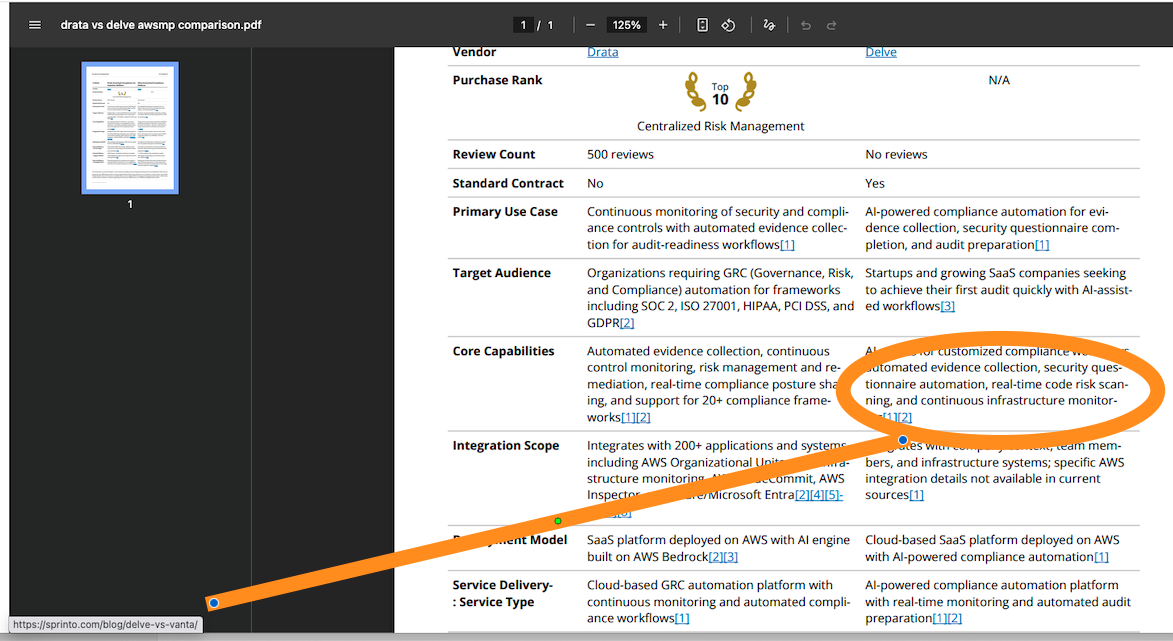
The linkages/reference embedding is not awesome either, but at least you’re getting some evidence for the AgentMode’s conclusions (which is better than some agentic marketplaces where there’s a bare recommendation of a solution with no justification or traceability).
You can always add your own URLs into the mix for AgentMode requests - which makes comparison / analysis it more specific but can take longer and does not necessarily resolve the confidence level in referencing. Plus you are now doing some of the job that AgentMode is supposed to do …
Sideways Glances
Also apparently AgentMode is caching or cookie-fying what you do in the browser, because your comparison sessions
persist in the project space (https://aws.amazon.com/marketplace/agentmode/#/project/proj-) for some period.
You can’t re-run them but you can edit them or add extra requirements - that feels a bit odd too, or if you were
doing that you’d want to keep the original version and make a modified copy.
In its current form, AgentMode is really AI content analysis, not agentic interaction - while you can poke AgentMode via a carefully constructed URL, its not neatly wrapped as a service (and isn’t under MCP either). To join the dots for agentic commerce, a few more pieces need to be linked up - its probably good that they’re kept separate at this point or agents might just buy random things and put them on your AWS bill.
The wrap up
AgentMode is still a fairly new feature of AWS Marketplace and no doubt it will be improved and extended over time. Still, at this point it seems hard to believe that a buyer with an AWS account would search Marketplace, then approach AgentMode for a comparison or for extended requirements analysis, review its outputs, and on the basis of that step into a contract forming process (whether public or private offer). Perhaps in a agentic commerce world that might be more likely, but for now, AgentMode seems like a convenient supporting/secondary analysis over a direct decision influence.